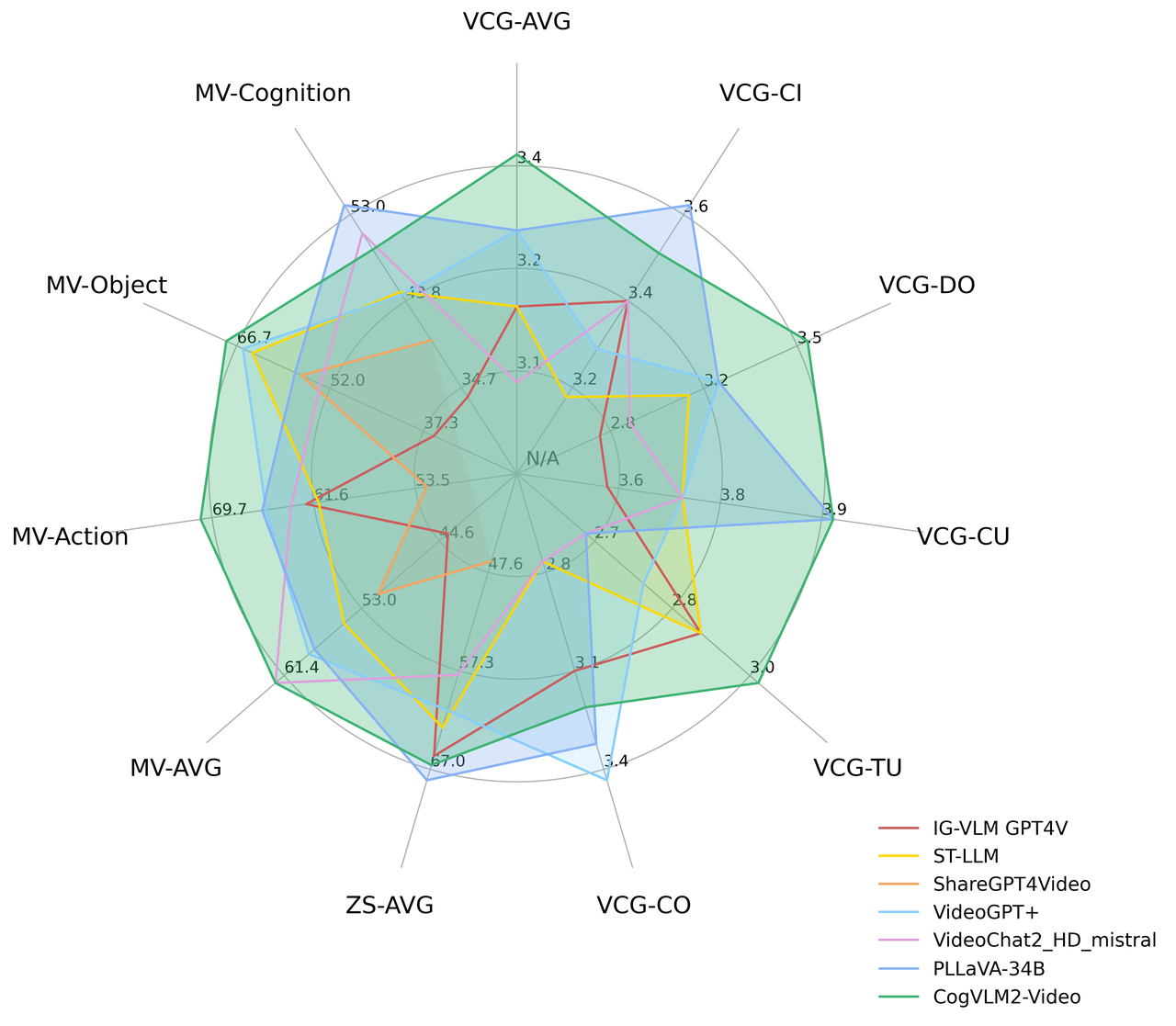
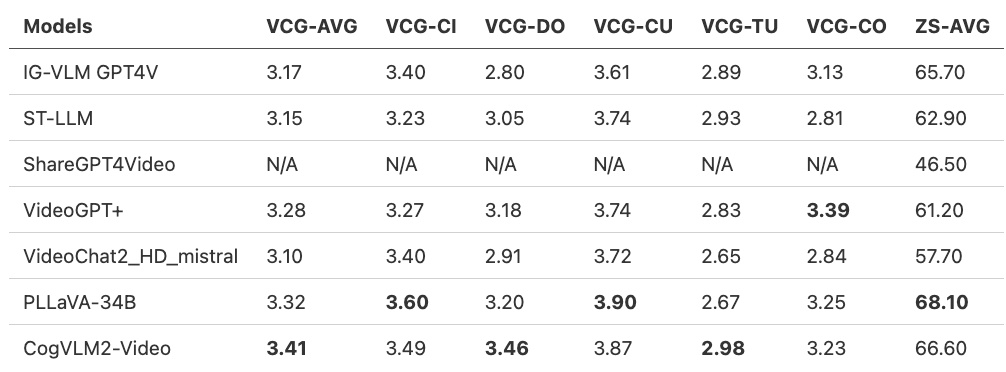
 Evaluation results on MVBench:
Evaluation results on MVBench: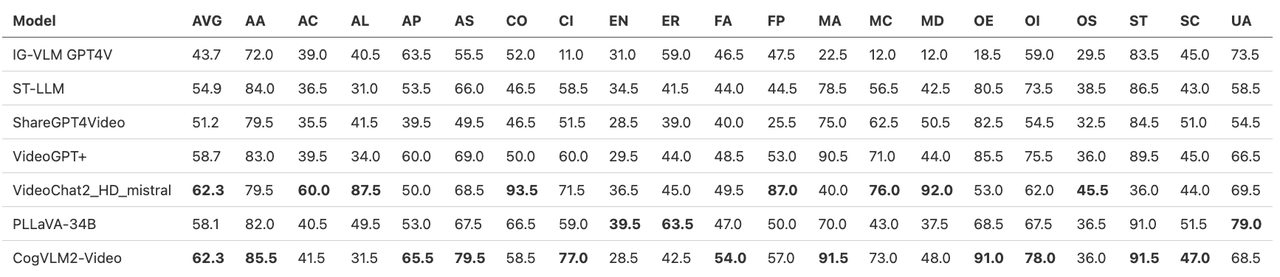
@article{hong2024cogvlm2,
title={CogVLM2: Visual Language Models for Image and Video Understanding},
author={Hong, Wenyi and Wang, Weihan and Ding, Ming and Yu, Wenmeng and Lv, Qingsong and Wang, Yan and Cheng, Yean and Huang, Shiyu and Ji, Junhui and Xue, Zhao and others},
journal={arXiv preprint arXiv:2408.16500},
year={2024}
}